


Lingo软件使用指南
摘要:本文介绍了Lingo软件的基本使用方法。从最基本的使用到复杂问题的解决,本文给出了比较详细的介绍。Lingo软件是美国Lindo公司的产品,主要用来求解优化问题。它是一个非常强大的软件,可以求解大部分优化问题,包括线性规划、二次规划、整数规划、运输问题等,是目前全球应用最广泛的优化软件之一。这里我们简单介绍它的使用方法。(下文中运算符号因无法打出,故使用a做代替)
一 进入Lingo
如果你的计算机已经安装了Lingo,只需要在桌面上双击Lingo的快捷方式,就可以进入Lingo。为了使自己的程序易于阅读,经常需要有一些注释,因此在编写程序中,每一行前面有感叹号的表示这一行是注释行,在程序运行中不起作用,希望初学者养成注释的好习惯。
二 建立数学模型和 Lingo模型语言
例1 在Lingo的命令窗口中输入下面的线性规划模型
!目标函数;
MAX = 100 * x1 150 * x2;
!第一个约束;
X1<= 100;
这个问题是一个典型的优化问题,通常称为运输问题。具体求解过程如下。
第一步:写出模型语言
1 构造目标函数。根据问题要求,可以设VOLUME_I_J表示从第I个仓库到第J个分厂运输原材料数。那么,总运费最小的目标函数为
MIN = 6 * VOLUME_1_1 2 * VOLUME_1_2
6 * VOLUME_1_3 7 * VOLUME_1_4
4 * VOLUME_1_5
·
·
·
8 * VOLUME_6_5 VOLUME_6_6 4 * VOLUME_6_7
3 * VOLUME_6_8;
很显然,这样输入太麻烦,如果用Lingo模型语言来描述则简洁的多。
首先将目标函数表示为我们熟悉的数学语言
Minimize aijCOSTij*VOLUMEij
然后将其转化为Lingo模型语言
MIN = @SUM( LINKS(I,J): COST(I,J) * VOLUME(I,J));
数学语言和Lingo模型语言之间的关系为:
数学语言 Lingo模型语言
Minimize MIN =aij @SUM( LINKS( I, J): )
COST ij COST(I,J)
* *
VOLUME ij VOLUME(I,J)
2 构造约束函数。
第j个分厂的需求:VOLUME_1_j VOLUME_2_j VOLUME_3_j
VOLUME_4_j VOLUME_5_j VOLUME_6_j = 35;
则每一个分厂的需求用数学语言描述为
ai VOLUMEij = DEMANDj, 对所有j 分厂
Lingo模型语言描述为
@FOR( VENDORS( J):
@SUM( WAREHOUSES( I): VOLUME( I, J)) = DEMAND( J));
数学语言和Lingo模型语言之间的关系为:
数学语言 Lingo模型语言
for all j inVENDORS @FOR( VENDORS( J): )
ai @SUM( WAREHOUSES( I): )
VOLUME ij VOLUME( I, J)
= =
DEMAND j DEMAND( J)
第i个仓库的供应:ai VOLUME ij <= CAP i ,
每一个仓库的供应能力约束为 aj VOLUME ij <= CAP i , 对所有i 仓库
Lingo模型语言描述为
@FOR( WAREHOUSES( I):
@SUM( VENDORS( J): VOLUME( I, J))<= CAPACITY( I));
这样,我们就把运输问题的两个约束都用Lingo模型语言写出来了。从而就得到了一个完整的模型:
MODEL:
MIN = @SUM( LINKS( I, J): COST( I, J) * VOLUME( I, J));
@FOR( VENDORS( J):
@SUM( WAREHOUSES( I): VOLUME( I, J)) =DEMAND( J));
@FOR( WAREHOUSES( I):
@SUM( VENDORS( J): VOLUME( I, J)) <=CAPACITY( I));
END
但是,我们还没有定义模型中的变量,且没有把已知数据传进来。
第二步:定义变量集合
在这个问题中,我们要定义三个集合,即:仓库集合、分厂集合及运输集合。
定义方式如下:
SETS:
WAREHOUSES / WH1 WH2 WH3 WH4 WH5 WH6/: CAPACITY;
VENDORS / V1 V2 V3 V4 V5 V6 V7 V8/ : DEMAND;
LINKS( WAREHOUSES, VENDORS): COST, VOLUME;
ENDSETS
在这个定义中,三个变量集合包含在SETS和ENDSETS之间。仓库集合命名为WAREHOUSES,其中包含六个元素WHi(即六个仓库),且每个元素都有一个共同属性是供应量,命名为CAPACITY。分厂集合命名为VENDORS,其中包含八个元素Vj(即八个分厂),每个元素都有一个共同属性是需求量,命名为DEMAND。运输集合是由前两个集合派生出来的,用LINKS( WAREHOUSES, VENDORS)来表示这种派生关系,它中间包含48个元素,表示了从6个仓库到8个分厂之间的运输情况,其中每一个元素有两个属性,运输费用COST和运输量VOLUME。这样,我们就把模型中需要的所有变量都定义过了。
第三步:输入模型数据
按照所定义的变量,输入数据,格式如下:
DATA:
CAPACITY = 60 55 51 43 41 52;
DEMAND = 35 37 22 32 41 32 43 38;
COST = 6 2 6 7 4 2 5 9
4 9 5 3 8 5 8 2
5 2 1 9 7 4 3 3
7 6 7 3 9 2 7 1
2 3 9 5 7 2 6 5
5 5 2 2 8 1 4 3;
ENDDATA
可以看出,所有输入的数据都必须包含在DATA和ENDDATA之间。
经过这三步之后,我们就可以得到一个完整的Lingo文件。
MODEL:
!六个仓库供应八个分厂的一个运输问题;
SETS:
WAREHOUSES/ WH1 WH2 WH3 WH4 WH5 WH6/: CAPACITY;
VENDORS/ V1 V2 V3 V4 V5 V6 V7 V8/: DEMAND;
LINKS (WAREHOUSES, VENDORS): COST, VOLUME;
ENDSETS
!目标函数;
MIN = @SUM( LINKS( I, J): COST( I, J) * VOLUME( I, J));
!分厂需求约束;
@FOR( VENDORS( J):
@SUM( WAREHOUSES( I): VOLUME( I, J)) =DEMAND( J));
!仓库供应约束;
@FOR( WAREHOUSES( I):
@SUM( VENDORS( J): VOLUME( I, J)) <=CAPACITY( I));
!输入数据;
DATA:
CAPACITY = 60 55 51 43 41 52;
DEMAND = 35 37 22 32 41 32 43 38;
COST = 6 2 6 7 4 2 5 9
4 9 5 3 8 5 8 2
5 2 1 9 7 4 3 3
7 6 7 3 9 2 7 1
2 3 9 5 7 2 6 5
5 5 2 2 8 1 4 3;
ENDDATA
END
求解可得:
Optimal solution found at step: 16
Objective value: 664.0000
求解报告(非零解)
Variable Value Reduced Cost
VOLUME( WH1, V2) 19.00000 0.0000000
VOLUME( WH1, V5) 41.00000 0.0000000
VOLUME( WH2, V4) 32.00000 0.0000000
VOLUME( WH2, V8) 1.000000 0.0000000
VOLUME( WH3, V2) 12.00000 0.0000000
VOLUME( WH3, V3) 22.00000 0.0000000
VOLUME( WH3, V7) 17.00000 0.0000000
VOLUME( WH4, V6) 6.000000 0.0000000
VOLUME( WH4, V8) 37.00000 0.0000000
VOLUME( WH5, V1) 35.00000 0.0000000
VOLUME( WH5, V2) 6.000000 0.0000000
VOLUME( WH6, V6) 26.00000 0.0000000
VOLUME( WH6, V7) 26.00000 0.0000000
通过前面两个例题,我们已经知道了如何利用Lingo软件去求解简单优化问题和比较复杂的优化问题。但是,这还不够,在变量集合的定义中,如果集合中的元素比较多,那么,采用枚举的定义方式就显得不合适;在输入数据时,如果数据量比较大,那么,采用在命令窗口中直接输入的方式就不可取,因此,我们必须去寻找更好的方法。下面我们就针对这两个问题来展开讨论。
三. 定义变量集合
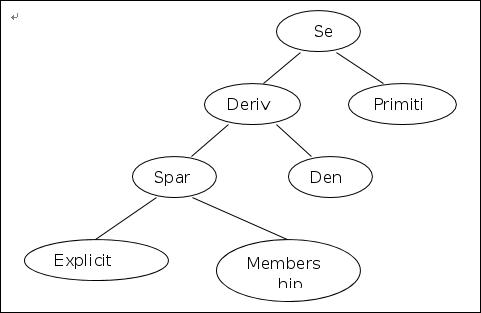
在Lingo模型语言中,变量集合分为两种类型:原始集合(Primitive)和派生集合(Derived)。在前面的例2中,仓库集合WAREHOUSES和分厂集合VENDORS就是原始集合,而运输集合是由这两个原始集合派生出来的,通常用LINKS( WAREHOUSES, VENDORS)来表示这个派生集合,这种派生属于完全派生,集合中包含了所有两个原始集合元素之间的各种可能搭配,因此,在例题中,这个派生集合中就包含了6´8=48个元素。
1.原始集合
一个原始集合的定义包含三部分,即
l集合名称setname,
l集合元素member,
l集合元素的属性attribute.
定义原始集合的语法为:
setname / member_list / [: attribute_list];
[ ]表示可选项,以下相同。
原始集合命名按照一般程序设计语言的命名规则。
元素列表中罗列出了集合中的元素,有两种方式,一是详细列表,即给每一个元素一个名字,把所有元素罗列出来,就象例2中仓库集合元素列表一样。WAREHOUSES / WH1 WH2 WH3 WH4 WH5 WH6/: CAPACITY;
另一种是简略列表,在简略列表中,不把集合中的元素按名字一一列出,而是采用下面的方式:
setname / 1..n / [: attribute_list];
仓库集合定义可以表示为
WAREHOUSES / 1..6/: CAPACITY;
对于元素比较多的集合,采用这样的方式是比较好的,但是,缺点就是元素名字只是用1,2…给出,不够直观。
元素属性列表中罗列出了集合中元素的所有属性,属性命名时按照一般程序设计语言的命名规则。属性可以有多个,例如我们对仓库集合元素增加一个位置属性LOCATION,则仓库集合定义可以表示为
WAREHOUSES / 1..6/: CAPACITY,LOCATION;
2 派生集合
一个派生集合的定义包含四部分,即
l集合名称setname,
l父亲集合,
l集合元素列表,
l集合元素的属性attribute.
定义派生集合的语法为:
setname( parent_set_list) [ / member_list /] [: attribute_list];
我们用下面的例子来说明,
SETS:
PRODUCT / A B/;
MACHINE / M N/;
WEEK / 1..2/;
ALLOWED( PRODUCT, MACHINE, WEEK);
ENDSETS
集合PRODUCT, MACHINE 和 WEEK是原始集合,集合ALLOWED 是由父亲集合 PRODUCT, MACHINE 和 WEEK派生出来的.它的元素为
ALLOWED Set Membership:
Index Member
1 (A,M,1)
2 (A,M,2)
3 (A,N,1)
4 (A,N,2)
5 (B,M,1)
6 (B,M,2)
7 (B,N,1)
8(B,N,2)
元素列表是可选项,如果省略掉,则默认为集合包含所有由父亲集合派生出来的元素,这种派生集合称之为稠密集合。就象上面的例子,包含8个元素。有时不需要派生集合中的所有元素,我们可以采用所谓的稀疏集合的方法,这时只需要指定派生集合的一个子集合即可。可以用两种方式来实现,一是详细列出子集合的所有元素,如
ALLOWED( PRODUCT, MACHINE, WEEK) / A M 1, A N 2, B N 1/;
这时,派生集合中的元素只有三个,即(A,M,1), (A,N,2), 和(B,N,1).
另一种是采用过滤技术来实现,我们仍然用一个例子来说明。考虑一个汽车集合TRUCKS,它是原始集合,集合中元素有属性CAPACITY,表示汽车的最大运载量,我们想得到运载量超过50000的所有汽车,这时可以采用过滤技术来实现。HEAVY_DUTY( TRUCKS) | CAPACITY( &1) #GT# 50000;
集合 HEAVY_DUTY是由TRUCKS派生出来的,它中的元素都是运载量超过50000的汽车,ï 是元素过滤的开始标志;&1 表示在过滤时把第一个父亲集合的元素放在其中,如果有第二个父亲集合,可以把第二个父亲集合的元素放在&2中;#GT#表示过滤的条件是‘大于’;50000是过滤的下界。上面的语句表示了由父亲集合TRUCKS派生出集合HEAVY_DUTY,它中间的元素的属性(即汽车的运载量)都是满足大于50000的。LINGO 中的逻辑运算符包括:
#EQ# equal
#NE# not equal
#GE# greater than or equal to
#GT# greater than
#LT# less than
#LE# less than or equal to
我们简单的总结集合之间的关系如下:
四.输入原始数据
在LINGO中,一个重要的部分就是数据部分,我们要输入的所有原始数据都要在这部分完成。数据部分以‘DATA:’开始,以‘ENDDATA’结束,所有输入数据包含在其中。数据输入的格式是:
attribute_list = value_list;
即我们需要把在变量集合部分定义好的集合赋以初值,给每一个集合属性列表赋以初值列表。我们以下面的例子来说明。
SETS:
SET1 /1..3/: X, Y;
ENDSETS
DATA:
X = 1 2 3;
Y = 4 5 6;
ENDDATA
首先定义了集合SET1,其中包含三个元素1,2,3,每个元素有两个属性X,Y。在数据部分,我们分别给两个属性赋初值,结果是元素1的X属性为1,Y属性为4,元素2的X属性为2,Y属性为5,元素3的X属性为3,Y属性为6。我们也可以采用下面的紧凑格式:
SETS:
SET1 /1..3/: X, Y;
ENDSETS
DATA:
X Y = 1 4
2 5
3 6;
ENDDATA
这样的数据输入方式对于比较小的问题是可行的,但是,对于规模比较大的问题,采用这样的数据输入方式显然是不可取的。LINGO提供了OLE 连接到 Excel, ODBC 连接到 databases, 以及与文本类型的数据文件的连接。
1.与文本型数据文件的连接
LINGO 与文本数据文件的连接函数中的数据载入函数是@FILE,使用这个函数可以把外部的文本型数据文件传入LINGO模型语言中来,它的语法为:@FILE( 'filename')。
我们仍然以运输问题为例来说明。在前面的例题中,模型语言如下:
MODEL:
!六个仓库供应八个分厂的一个运输问题;
SETS:
WAREHOUSES/ WH1 WH2 WH3 WH4 WH5 WH6/: CAPACITY;
VENDORS/ V1 V2 V3 V4 V5 V6 V7 V8/: DEMAND;
LINKS (WAREHOUSES, VENDORS): COST, VOLUME;
ENDSETS
!目标函数;
MIN = @SUM( LINKS( I, J): COST( I, J) * VOLUME( I, J));
!分厂需求约束;
@FOR( VENDORS( J):
@SUM( WAREHOUSES( I): VOLUME( I, J)) =DEMAND( J));
!仓库供应约束;
@FOR( WAREHOUSES( I):
@SUM( VENDORS( J): VOLUME( I, J)) <=CAPACITY( I));
!输入数据;
DATA:
CAPACITY = 60 55 51 43 41 52;
DEMAND = 35 37 22 32 41 32 43 38;
COST = 6 2 6 7 4 2 5 9
4 9 5 3 8 5 8 2
5 2 1 9 7 4 3 3
7 6 7 3 9 2 7 1
2 3 9 5 7 2 6 5
5 5 2 2 8 1 4 3;
ENDDATA
END
我们使用函数@FILE来简化模型语言的书写
MODEL:
!六个仓库供应八个分厂的一个运输问题;
SETS:
WAREHOUSES / @FILE( 'WIDGETS2.LDT')/: CAPACITY;
VENDORS / @FILE( 'WIDGETS2.LDT')/ : DEMAND;
LINKS (WAREHOUSES, VENDORS): COST, VOLUME;
ENDSETS
!目标函数;
MIN = @SUM( LINKS( I, J): COST( I, J) * VOLUME( I, J));
!分厂需求约束;
@FOR( VENDORS( J):
@SUM( WAREHOUSES( I): VOLUME( I, J)) =DEMAND( J));
!仓库供应约束;
@FOR( WAREHOUSES( I):
@SUM( VENDORS( J): VOLUME( I, J)) <=CAPACITY( I));
!输入数据;
DATA:
CAPACITY = @FILE( 'WIDGETS2.LDT');
DEMAND = @FILE( 'WIDGETS2.LDT');
COST = @FILE( 'WIDGETS2.LDT');
ENDDATA
END
原始数据存放在文本型数据文件WIDGETS2.LDT中,该文件的内容如下:
!仓库列表;
WH1 WH2 WH3 WH4 WH5 WH6 ~
!分厂列表;
V1 V2 V3 V4 V5 V6 V7 V8 ~
!仓库储存量列表;
60 55 51 43 41 52 ~
!分厂需求列表;
35 37 22 32 41 32 43 38 ~
!单位运输费用列表;
6 2 6 7 4 2 5 9
4 9 5 3 8 5 8 2
5 2 1 9 7 4 3 3
7 6 7 3 9 2 7 1
2 3 9 5 7 2 6 5
5 5 2 2 8 1 4 3
文件WIDGETS2.LDT的结构最好按照模型中的调用顺序来组织。文件中经常出现的符号‘ ~ ’是记录结束标志,每一次调用文件WIDGETS2.LDT传进去一条记录,最后一条记录没有结束标志‘ ~ ’,调用结束后系统会自动关闭文件,如果给最后一条记录加上记录结束标志‘ ~ ’,那么调用结束后系统不会关闭数据文件,这时往往会给下一个数据文件的调用带来麻烦。
LINGO还提供了一个与文本型数据文件连接的数据载出函数@TEXT,使用这个函数可以把求解的结果数据保存到外部文本文件中。它的语法规则是:
@TEXT( ['filename'])
如果省略掉数据文件名,则系统会把结果输出到命令窗口。我们在下面的模型语言中将计算出的非零的VOLUME的值存入文本文件OUT.TXT中,
MODEL:
!六个仓库供应八个分厂的一个运输问题;
SETS:
WAREHOUSES/ @FILE( 'Widgets2.LDT')/: CAPACITY;
VENDORS/ @FILE( 'Widgets2.LDT')/: DEMAND;
LINKS (WAREHOUSES, VENDORS): COST, VOLUME;
ENDSETS
!目标函数;
MIN = @SUM( LINKS( I, J): COST( I, J) * VOLUME( I, J));
!分厂需求约束;
@FOR( VENDORS( J):
@SUM( WAREHOUSES( I): VOLUME( I, J)) =DEMAND( J));
!仓库供应约束;
@FOR( WAREHOUSES( I):
@SUM( VENDORS( J): VOLUME( I, J)) <=CAPACITY( I));
!输入数据;
DATA:
CAPACITY=@FILE( 'Widgets2.LDT');
DEMAND=@FILE( 'Widgets2.LDT');
COST=@FILE( 'Widgets2.LDT');
@TEXT( 'OUT.TXT') = VOLUME;
ENDDATA
END
我们可以把得到的文本型数据文件OUT.TXT转换成EXCEL文件,也可以转换成ACCESS文件。
2. 与EXCEL数据文件连接
(1)数据文件的载入
数据文件载入有两个函数:@OLE和@WKX,如果我们的数据文件保存为*.XLS
型,则数据文件的传入和传出用函数@OLE,如果数据文件保存为*.WK4型,则必须用函数@WKX来处理。
@OLE的语法是:
variable_list = @OLE('spreadsheet_file',[ range_name_list]);
例1:PRICE = @OLE( 'C:\XLS\MYDATA.XLS', 'MYPRICES');的含义是打开C盘上XLS文件夹中名字是MYDATA.XLS的文件,从中读取名称为‘MYPRICES’的所有数据传给变量‘PRICE’。
例2:COST, CAPACITY = @OLE( 'SPECS.XLS');的含义是在EXCEL中寻找名字是SPECS.XLS的文件,读取名称为COST和CAPACITY的数据传给变量COST, CAPACITY。
我们以运输问题为例来详细说明。
MODEL:
!六个仓库供应八个分厂的一个运输问题;
SETS:
WAREHOUSES/WH1,WH2,WH3,WH4,WH5,WH6/: CAPACITY;
VENDORS/ V1 V2 V3 V4 V5 V6 V7 V8/: DEMAND;
LINKS (WAREHOUSES, VENDORS): COST, VOLUME;
ENDSETS
!目标函数;
MIN = @SUM( LINKS( I, J): COST( I, J) * VOLUME( I, J));
!分厂需求约束;
@FOR( VENDORS( J):
@SUM( WAREHOUSES( I): VOLUME( I, J)) =DEMAND( J));
!仓库供应约束;
@FOR( WAREHOUSES( I):
@SUM( VENDORS( J): VOLUME( I, J)) <=CAPACITY( I));
!输入数据;
DATA:
!从EXCEL中载入数据;
CAPACITY, DEMAND, COST = @OLE( 'E: \Lingo使用指南\SHIPDATA.XLS');
ENDDATA
END
这里要说明的是,在使用函数@OLE时,我们首先要对数据文件SHIPDATA中的
原始数据指定名称(即指定哪些数据是CAPACITY,哪些是DEMAND,哪些是COST,以及哪些单元格准备存放结果VOLUME)。而且这个函数的使用必须要求EXCEL是5.0以上的版本。
@WKX的语法是:
variable_list = @WKX( 'spreadsheet_file',[ range_name_list]);
对于运输问题,如果我们的数据文件保存为SHIPDATA.WK4,那么就可以使用这个函数,具体使用时只需把数据输入部分稍做修改:
CAPACITY, DEMAND, COST = @WKX( 'E: \Lingo使用指南\SHIPDATA.WK4',
'CAPACITY', 'DEMAND', 'COST');
可以看出,这两个函数的使用非常相似。但是,对于数据输出,它们的使用却有较大差别。
(2)数据传出到文件
数据传出仍然是这两个函数:@OLE和@WKX。首先介绍@OLE的使用。它的语法是:
@OLE('spreadsheet_file',[range_name_list]) = variable_list;
和数据传入的区别在于:
@OLE( ) = variable_list; 变量数据传出到文件
variable_list = @OLE( ); 文件中数据传入给变量.
我们以运输问题为例来详细说明。
MODEL:
!六个仓库供应八个分厂的一个运输问题;
SETS:
WAREHOUSES/WH1,WH2,WH3,WH4,WH5,WH6/: CAPACITY;
VENDORS/ V1 V2 V3 V4 V5 V6 V7 V8/: DEMAND;
LINKS (WAREHOUSES, VENDORS): COST, VOLUME;
ENDSETS
!目标函数;
MIN = @SUM( LINKS( I, J): COST( I, J) * VOLUME( I, J));
!分厂需求约束;
@FOR( VENDORS( J):
@SUM( WAREHOUSES( I): VOLUME( I, J)) =DEMAND( J));
!仓库供应约束;
@FOR( WAREHOUSES( I):
@SUM( VENDORS( J): VOLUME( I, J)) <=CAPACITY( I));
!输入数据;
DATA:
!从EXCEL中载入数据;
CAPACITY, DEMAND, COST = @OLE( 'E: \Lingo使用指南\SHIPDATA.XLS');
!将数据传出到文件
@OLE( ' E:\Lingo使用指南\SHIPDATA.XLS ','VOLUME') = VOLUME;
ENDDATA
END
计算结束后,系统会自动地把VOLUME的值传出到文件SHIPDATA.XLS(注意这个文件和数据载入文件是同一个文件)。如果使用@WKX来传出数据,则比用@OLE要复杂一些。@WKX的语法是:
@WKX( 'template_spreadsheet_file', 'output_spreadsheet_file',
[ range_name_list]) = variable_list;
其中的参数template_spreadsheet_file是载入数据的数据文件,其中必须指定所计算的变量的单元格,且必须将值设置为0。 output_spreadsheet_file是数据输出文件,名字要求和原文件不同,在这个文件中,必须指定变量的单元格,准备接受输出的数据。
对于运输问题,我们的数据文件为SHIPDATA.WK4,具体使用函数@WKX时只需把数据输出部分稍做修改:
@WKX( ' E:\Lingo使用指南\SHIPDATA.WK4',
' E:\Lingo使用指南\SHIPDATA2.WK4', 'VOLUME') = VOLUME;
计算结束后,我们就得到文件SHIPDATA2.WK4,在EXCEL中打开如下:
表
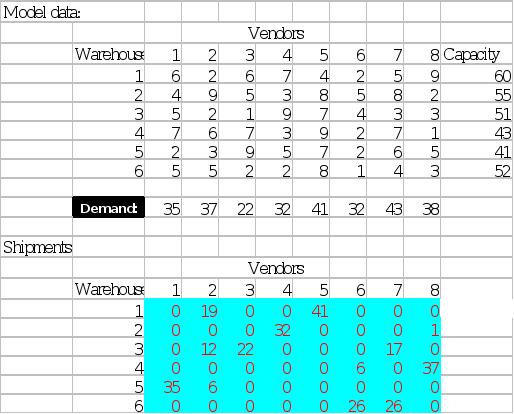
中浅兰色区域中的数据为计算结果VOLUME的值。
五.变量域函数
LINGO中,如果不特别指出,系统默认所有变量是非负连续变量。如果模型中有超越这个范围的数据,必须利用变量域函数来说明。常用的变量域函数有四个:
@GIN 限制变量只能取整数值,
@BIN 限制变量取0,1值,
@FREE 允许变量取任意实数值,
@BND 限制变量在一定范围内取值.
1.整数变量函数@GIN
整数规划问题是非常广泛的一类优化问题,它要求问题中的变量取整数值或
部分变量取整数值。我们首先介绍一般取整函数@GIN。语法为:
@GIN( variable_name);
我们举例来说明这个函数的使用。这个例子考虑的是一家热狗店如何组织员工,能使所雇佣的员工数最少的问题。程序如下:
SETS:
DAYS / MON TUE WED THU FRI SAT SUN/:REQUIRED, START;
ENDSETS
DATA:
REQUIRED = 20 12 18 16 19 14 12;
ENDDATA
MIN = @SUM( DAYS( I): START( I));
@FOR( DAYS( J):
@SUM( DAYS( I) | I #LE# 5: START( @WRAP( J - I 1, 7)))
>= REQUIRED( J)
);
求解可得:
Optimal solution found at step: 7
Objective value: 23.66667
Variable Value Reduced Cost
START( MON) 9.666667 0.0000000
START( TUE) 0.0000000 -0.2980232E-07
START( WED) 3.666667 0.0000000
START( THU) 5.666667 0.0000000
START( FRI) 0.0000000 -0.2980232E-07
START( SAT) 4.666667 0.0000000
START( SUN) 0.0000000 0.3333333
由于我们没有指明变量START(I)为整数变量,所以系统默认为非负连续变量,从而得到星期一需要安排9.666667个员工的事情。这是不符合实际的,因此,为了解决这个问题,我们可以使用函数@GIN来处理变量。修改后的程序如下:
SETS:
DAYS / MON TUE WED THU FRI SAT SUN/:REQUIRED, START;
ENDSETS
DATA:
REQUIRED = 20 12 18 16 19 14 12;
ENDDATA
MIN = @SUM( DAYS( I): START( I));
@FOR( DAYS( J):
@SUM( DAYS( I) | I #LE# 5: START( @WRAP( J - I 1, 7)))
>= REQUIRED( J)
);
@FOR(DAYS( I): @GIN( START( I)));
得到的结果为:
Optimal solution found at step: 6
Objective value: 24.00000
Branch count: 1
Variable Value Reduced Cost
START( MON) 9.000000 1.000000
START( TUE) 3.000000 1.000000
START( WED) 1.000000 1.000000
START( THU) 6.000000 1.000000
START( FRI) 0.0000000 1.000000
START( SAT) 4.000000 1.000000
START( SUN) 1.000000 1.000000
2.布尔变量函数@BIN
在一些整数规划中,变量只能取0或1,这种问题称为0-1规划,限制变量取0
或1的函数是@BIN。使用的语法为:
@BIN( variable_name);
我们给出下面的例子:
SETS:
ITEMS / ANT_REPEL, BEER, BLANKET,
BRATWURST, BROWNIES, FRISBEE, SALAD,
WATERMELON/:
INCLUDE, WEIGHT, RATING;
ENDSETS
DATA:
WEIGHT RATING =
1 2
3 9
4 3
3 8
3 10
1 6
5 4
10 10;
KNAPSACK_CAPACITY = 15;
ENDDATA
MAX = @SUM( ITEMS: RATING * INCLUDE);
@SUM( ITEMS: WEIGHT * INCLUDE) <= KNAPSACK_CAPACITY;
@FOR( ITEMS: @BIN( INCLUDE));
程序执行结果如下:
Optimal solution found at step: 10
Objective value: 38.00000
Branch count: 0
Variable Value
INCLUDE( ANT_REPEL) 1.000000
INCLUDE( BEER) 1.000000
INCLUDE( BLANKET) 1.000000
INCLUDE( BRATWURST) 1.000000
INCLUDE( BROWNIES) 1.000000
INCLUDE( FRISBEE) 1.000000
INCLUDE( SALAD) 0.000000
INCLUDE( WATERMELON) 0.000000
3.自由变量函数@FREE
大部分优化问题没有对变量的取值给出要求,也即变量可以取到从负无穷到
正无穷的任意实数。这就需要在程序中对变量作出说明,用函数@FREE可以达到这个目的。它的语法是:
@FREE( variable_name);
我们来看一个关于预测的例子,程序如下:
SETS:
PERIODS /1..8/: OBSERVED, PREDICT,ERROR;
QUARTERS /1..4/: SEASFAC;
ENDSETS
DATA:
OBSERVED = 10 14 12 19 14 21 19 26;
ENDDATA
MIN = @SUM( PERIODS: ERROR ^ 2);
@FOR( PERIODS: ERROR = PREDICT - OBSERVED);
@FOR( PERIODS( P): PREDICT( P) =
SEASFAC( @WRAP( P, 4))* ( BASE P * TREND));
@SUM( QUARTERS: SEASFAC) = 4;
@FOR( PERIODS: @FREE( ERROR));
结果如下:
Optimal solution found at step: 27
Objective value: 1.822561
Variable Value
BASE 9.718875
TREND 1.553017
PREDICT( 1) 9.311819
PREDICT( 2) 14.10136
PREDICT( 3) 12.85212
PREDICT( 4) 18.80620
PREDICT( 5) 14.44367
PREDICT( 6) 20.93171
PREDICT( 7) 18.40496
PREDICT( 8) 26.13944
ERROR( 1) -0.6881806
ERROR( 2) 0.1013619
ERROR( 3) 0.8521245
ERROR( 4) -0.1938018
ERROR( 5) 0.4436698
ERROR( 6) -0.6828707E-01
ERROR( 7) -0.5950383
ERROR( 8) 0.1394362
SEASFAC( 1) 0.8261097
SEASFAC( 2) 1.099529
SEASFAC( 3) 0.8938788
SEASFAC( 4) 1.180482
4. 变量上下界的设定
在许多问题中,需要对变量设置上下界,在EXCEL中,函数@BND可以实现这个目的。它的语法是:
@BND( lower_bound, variable_name, upper_bound);
例如:
1: @BND( -1, X, 1);
设置变量X在区间[-1,1]内取值;
2: @BND( 100, QUANTITY( 4), 200);
设置变量QUANTITY( 4)在100到 200之间取值;
3: @FOR( ITEMS: @BND( 10, Q, 20));
设置集合ITEMS中所有元素的Q属性值在 10到20之间;
4: @FOR( ITEMS: @BND( QL, Q, QU));
设置集合ITEMS中所有元素的Q属性值在QL 到QU 之间(QL和QU必须在
数据输入部分给定具体值)。
我们上面所提到的仅仅是LINGO的很少一部分内容,但是,任何一个问题,用LINGO模型语言写出来,都有这五个基本的组成部分:
1.变量定义;
2.数据输入;
3.目标函数;
4.约束;
5.变量取值范围。
具体使用中如果遇到问题,可以参考LINGO的帮助系统。
matlab 在最优化问题中的应用
1 线性优化
在matlab 中.线性优化问题由lp函数求解
x=lp(f,A,b) (f为目标函数,A,b满足约束条件
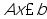
)
x=lp(f,A,b,vlb,vub) (vib≤x≤vub)
x=lp(f,A,b,vlb,vub,x0) (x0为初值)
x= lp(f,A,b,vlb,vub,x0,n) (前n个等式约束)
[x,lambda]=lp(f,A,b)
例 求下面的优化问题

c=[-5 4 2];
a=[6 -1 1;1 2 4];
b=[8 10];
vlb=[-1 0 0];
vub=[3 2];
[x,lam]=lp(c,a,b,vlb,vub)
说明 x 为最优解,lam说明 条件
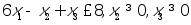
起了作用
例 某车间生产A和B两种产品.为了生产A和B,所需的原料未必为2个和3个单位,而所需的工时分别为4个和2个单位,现在可以应用的原料为100个单位.工时为120个单位,每生产一台A和B分别可获得利润6元和4元,应当安排生产A,B各多少台,才能获得最大利润?
建立最优化模型
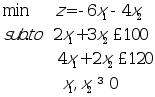
c=[-6 -4];
a=[2 3;4 2];
b=[100 120];
vlb=[0 0];
vub=[];
[x,lam]=lp(c,a,b,vib,vub)
2 二次优化
二次优化函数 qp
x=qp(H,f,A,b) 解决如下形式二次规划
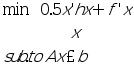
x=qp(H,f,A,b,vlb,vub) (vlb≤x≤vub)
x=qp(H,f,A,b,vlb,vub,x0) (x0为初值)
x= qp(H,f,A,b,vlb,vub,x0,n) (前n个等式约束)
[x,lambda]=qp(H,f,A,b)
例 求解如下二次优化问题
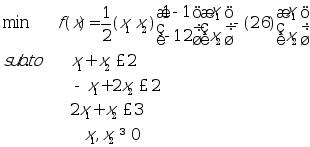
h=[1 -1;-1 2];
c=[-2 -6];
a=[1 1;-1 2;2 1];
b=[2 2 3];
vlb=[0 0];
vub=[]
[x,lam]=qp(h,c,a,b,vlb,vub)
3 非线性无约束优化问题
函数 fmin 单变量的最小函数值
调用格式
x=fmin(‘f’,x1,x2) (f 为目标函数. x1<x<x2)
x=fmin(‘f’,x1,x2,options)
(options 为控制参数,
若options(1)为负值,则显示中间计算过程,默认值为options(1)=0,
若options(2)为结果x的误差范围,默认值为1.e-4
若options(14)为函数求值的最大次数,默认值为options(14)=500)
x=fmin(‘f’,x1,x2,options,p1,p2) (p1,p2 为输入到目标函数的自变量值)
[x,options]=fmin() (返回options(10)中步数的计算值)
例 计算函数式
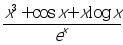
在(0,1)范围内的最小值点
fmin(‘(x^3 cos(x) x*log(x))/exp(x)’,0,1)
函数 fmins 多变量最小函数值
调用格式
x=fmins(‘f’,x0)
x=fmins(‘f’,x0,options)
x=fmins(‘f’,x0,options,[],p1,p2)
注 fmins 使用nelder-mead 型简单搜寻方法
例 求
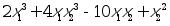
的最小值点/
fmins(‘2*x(1)^3 4*x(1)*x(2)^3-10x(1)*x(2) x(2)^2’,[0,0])
函数 fminu 多变量函数最小值时的变量值
调用格式
x=fminu(‘fun’,x0) (fun为目标函数,x0为初值)
x=fminu(‘fun’,x0,options)
x=fminu(‘fun’,x0,options,’gradfun’) (gradfun为参数函数)
x=fminu(‘fun’,x0,options,’gradfun’,p1,p2)
[x,options]=fminu(‘fun’,x0) (以最优化方法返回所用参数值)
例 求函数
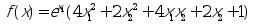
的最小值
fun=’exp(x(1))*(4*x(1)^2 2*x(2)^2 4*x(2)*x(1) 2*x(2) 1)’;
x0=[-1,1];
options=[];
[x,options]=fminu(fun,x0,opyions);
x
opyions(8)
options(10)
,
相关文章
-

男人海洋(男人海洋简谱)
其实男人海洋的问题并不复杂,但是又很多的朋友都不太了解男人海洋简谱,因此呢,今天小编就来为大家分享男人海洋的一些知识,希望可以帮助到大家,下面我们一起来看看这个问题的分析吧!1男人海洋表达了什么情感? 歌曲大意是说男人的感情应该像海洋:痴情的男人甘心为所爱默默承受痛苦而不让她发现、烦恼,就像海洋,即使有风暴也要保持平静的模样;温柔的男人像海洋般宽广,默默守护自己的所爱,让她飞翔。男人海洋可以象征着男人的勇气、力量和冒险精神,表达出男性追求自由、独立和挑战...
-

无名小店创业项目(无名店铺门头照片)
本篇文章给大家谈谈无名小店创业项目,以及无名店铺门头照片对应的知识点,文章可能有点长,但是希望大家可以阅读完,增长自己的知识,最重要的是希望对各位有所帮助,可以解决了您的问题,不要忘了收藏本站喔。1自己创业开店开什么比较能挣钱 早餐店,这是一个非常累人、很不起眼、很多人都看不起的项目,不少创业者都不愿意做这个项目,认为卖早餐不仅累人,而且也不赚钱,卖一份早餐才几块钱,总觉得掉了自己档次。网络销售:通过电子商务平台开设网店,销售自己或其他供应商的产品。餐饮...
-

红肉(红肉菠萝蜜)
大家好,如果您还对红肉不太了解,没有关系,今天就由本站为大家分享红肉的知识,包括红肉菠萝蜜的问题都会给大家分析到,还望可以解决大家的问题,下面我们就开始吧!1红肉指的是哪些肉? 1、红肉有猪肉、兔肉、牛肉、羊肉、鹿肉等所有哺乳动物的肉。红肉在营养学的范畴中指的是在烹饪前呈现岀红色的肉,哺乳动物的肉里一般含有肌红蛋白,切开后会呈现出红色。2、红肉是指兔肉、牛肉、羊肉、鹿肉、马肉、驴肉等等这些肉类。兔肉 兔肉包括家兔肉和野兔肉两种,家兔肉又称为菜兔肉。兔肉全...
-
小伙25天创业项目(20岁小伙创业)
大家好,今天来为大家分享小伙25天创业项目的一些知识点,和20岁小伙创业的问题解析,大家要是都明白,那么可以忽略,如果不太清楚的话可以看看本篇文章,相信很大概率可以解决您的问题,接下来我们就一起来看看吧!1适合年轻人创业的项目有哪些? 潮流行业 年轻人,学习快,接受能力强,具备新思维,新理念,这些都是优势,对于一些潮流性的行业是非常适合年轻人去拓展。譬如冰吧,DIY, 连锁加盟,会所,公众号等等这些都是年轻创业者的舞台。年轻人创业可以考虑开美甲店、网店和...
-
鬼虾价格行情今日(鬼虾养殖技术和环境)
大家好,感谢邀请,今天来为大家分享一下鬼虾价格行情今日的问题,以及和鬼虾养殖技术和环境的一些困惑,大家要是还不太明白的话,也没有关系,因为接下来将为大家分享,希望可以帮助到大家,解决大家的问题,下面就开始吧!1一个去壳斑节虾多少克 1、到400克。斑节对虾俗称鬼虾、草虾、花虾、竹节虾、斑节虾、牛形对虾,联合国粮农组织通称大虎虾。自成熟个体平均体长一般可达300到350毫米,平均体质量为350到400克。2、黑虎虾黑虎虾在印度和西太平洋很是多见,其别名为鬼...
-
A52参数配置(三星a52和a53对比)
大家好,今天来为大家分享A52参数配置的一些知识点,和三星a52和a53对比的问题解析,大家要是都明白,那么可以忽略,如果不太清楚的话可以看看本篇文章,相信很大概率可以解决您的问题,接下来我们就一起来看看吧!1oppoa52手机参数 主屏分辨率:2400x1080像素。屏幕像素密度:405ppi。CPU型号:高通 骁龙665。机身颜色:黑色,星耀白。操作系统:Color OS 1。oppo a52参数如下:OPPOA52正面选用单挑孔全面屏手机设计方案,...